Методы и алгоритмы сэмплинга в анализе данных
Содержание:
- Frequently asked questions about sampling
- Sampling thresholds
- Критерии оценки сэмплинг акций
- использовать
- Моделирование
- Population vs sample
- Особенности применения сэмплинга
- What is Sampling?
- Sampling Error vs. Non-sampling Error
- Описание алгоритма
- Какой бывает сэмплинг?
- Виды сэмплинга
- Как организовать сэмплинг
- Примечания[править]
- Литература
- Introduction
- Downsampling
Frequently asked questions about sampling
-
What is sampling?
-
A sample is a subset of individuals from a larger population. Sampling means selecting the group that you will actually collect data from in your research. For example, if you are researching the opinions of students in your university, you could survey a sample of 100 students.
In statistics, sampling allows you to test a hypothesis about the characteristics of a population.
-
Why are samples used in research?
-
Samples are used to make inferences about populations. Samples are easier to collect data from because they are practical, cost-effective, convenient and manageable.
-
What is probability sampling?
-
means that every member of the target population has a known chance of being included in the sample.
Probability sampling methods include simple random sampling, systematic sampling, stratified sampling, and cluster sampling.
-
What is non-probability sampling?
-
In , the sample is selected based on non-random criteria, and not every member of the population has a chance of being included.
Common non-probability sampling methods include convenience sampling, voluntary response sampling, purposive sampling, snowball sampling, and quota sampling.
-
What is multistage sampling?
-
In multistage sampling, or multistage cluster sampling, you draw a sample from a population using smaller and smaller groups at each stage.
This method is often used to collect data from a large, geographically spread group of people in national surveys, for example. You take advantage of hierarchical groupings (e.g., from state to city to neighborhood) to create a sample that’s less expensive and time-consuming to collect data from.
-
What is sampling bias?
-
Sampling bias occurs when some members of a population are systematically more likely to be selected in a sample than others.
Sampling thresholds
Default reports are not subject to sampling.
Ad-hoc queries of your data are subject to the following general thresholds for sampling:
- Analytics Standard: 500k sessions at the property level for the date range you are using
- Analytics 360: 100M sessions at the view level for the date range you are using
In some circumstances, you may see fewer sessions sampled. This can result from the complexity of your Analytics implementation, the use of view filters, query complexity for segmentation, or some combination of those factors. Although we make a best effort to sample up to the thresholds described above, it’s normal to sometimes see slightly fewer sessions returned for an ad-hoc query.
Критерии оценки сэмплинг акций
Сначала нужно выявить количество продаж в такой же день с учётом сезона, дня недели, времени проведения компании.
Потом при помощи промоутеров или данных точки продаж, нужно зафиксировать объём продаж в период семплинг мероприятия. Если всё прошло успешно, то рост продаж во время кампании будет от 150% до 250% от объёма продаж в обычное время.
Имея необходимые данные, не сложно узнать стоимость контакта с покупателем: для этого расходы на кампанию нужно разделить на число клиентов, которым раздали саше.
А стоимость результативного контакта подсчитывается так: расходы на кампанию разделим на количество проданной продукции.
Необходимо также учитывать и то, что частота повторных покупок будет зависеть от периода жизни товара, поэтому детальный анализ, в ряде случаев, можно сделать только по истечении нескольких месяцев после организации семплинга.
использовать
К музыкантам или продюсерам, которые начали сэмплирование первыми, относятся:
- Пьер Шеффер (1948, musique concrète )
- Базз Клиффорд (1960, Baby Sittin ‘Boogie )
- Джон Кейдж (1962, Уильям Микс )
- Уилл Брандес и Маленькая Элизабет — (1962, Baby Twist — голоса малышей Элизабет являются «образцами»)
- Битлз (1968, Revolution 9 )
- CAN (1969, в разрезе )
- Pink Floyd (1973, Деньги )
- Пульсирующий хрящ (1977, второй годовой отчет )
- Куртис Блоу (19?, Хип-хоп )
- Карлос Перон (1980 Solid Pleasure)
- Кейт Буш (1980, Бабушка )
- Хуберт Богнермайр , Харальд Зусацрадер (1981, «Эрденкланг»)
- Жан Мишель Жарр (1981, Магнитные поля )
- Брайан Ино (1981, Моя жизнь в кустах призраков )
- Питер Гэбриэл (1982, Shock The Monkey )
- Тревор Хорн и др. с искусством шума (1983)
- Да (1983, владелец одинокого сердца)
- Арно Штеффен (1983, хит )
- Катушка (1984, прозрачная )
- Причуда Гаджет (1984, Новые люди )
- Depeche Mode (1983, конвейер )
- Хольгер Хиллер (1983, Связка гнили в яме )
- Kraftwerk (1986, электрическое кафе )
- DJ Shadows Album Endtroduction ….. — первый альбом, состоящий только из сэмплов.
- Компьютерные жокеи стали первым коммерчески успешным чартерным коллективом в 1997 году с семплами и автономным компьютером (без дополнительного звукового генератора / MIDI) вживую со своими собственными аранжировками.
- Джон Освальд использовал в своей Plunderphonics впервые микро выборки , Акуфно это привело в доме на контексте
Моделирование
Мы можем полностью отойти от теоретического решения и решить задачу «в лоб». Благодаря языку R теперь это сделать очень просто. Чтобы ответить на вопрос, в какую мы ошибку получим при сэмплировании, можно просто сделать тысячу сэмплирований и посмотреть, какую ошибку мы получаем.
Подход такой:
- Берем разные коэффициенты конверсии (от 0.01% до 50%).
- Берем 1000 сэмплов по 10, 100, 1000, 10000, 50000, 100000, 250000, 500000 элементов в выборке
- Считаем коэффициент конверсии по каждой группе сэмплов (1000 коэффициентов)
- Строим гистограмму по каждой группе сэмплов и определяем, в каких пределах лежат 60%, 80% и 90% наблюдаемых коэффициентов конверсии.
Код на R генерирующий данные:
В результате мы получаем следующую таблицу (дальше будут графики, но детали лучше видны в таблице).
| Коэффициент конверсии | Размер сэмпла | 5% | 10% | 20% | 80% | 90% | 95% |
|---|---|---|---|---|---|---|---|
| 0.0001 | 10 | ||||||
| 0.0001 | 100 | ||||||
| 0.0001 | 1000 | 0.001 | |||||
| 0.0001 | 10000 | 0.0002 | 0.0002 | 0.0003 | |||
| 0.0001 | 50000 | 0.00004 | 0.00004 | 0.00006 | 0.00014 | 0.00016 | 0.00018 |
| 0.0001 | 100000 | 0.00005 | 0.00006 | 0.00007 | 0.00013 | 0.00014 | 0.00016 |
| 0.0001 | 250000 | 0.000072 | 0.0000796 | 0.000088 | 0.00012 | 0.000128 | 0.000136 |
| 0.0001 | 500000 | 0.00008 | 0.000084 | 0.000092 | 0.000114 | 0.000122 | 0.000128 |
| 0.001 | 10 | ||||||
| 0.001 | 100 | 0.01 | |||||
| 0.001 | 1000 | 0.002 | 0.002 | 0.003 | |||
| 0.001 | 10000 | 0.0005 | 0.0006 | 0.0007 | 0.0013 | 0.0014 | 0.0016 |
| 0.001 | 50000 | 0.0008 | 0.000858 | 0.00092 | 0.00116 | 0.00122 | 0.00126 |
| 0.001 | 100000 | 0.00087 | 0.00091 | 0.00095 | 0.00112 | 0.00116 | 0.0012105 |
| 0.001 | 250000 | 0.00092 | 0.000948 | 0.000972 | 0.001084 | 0.001116 | 0.0011362 |
| 0.001 | 500000 | 0.000952 | 0.0009698 | 0.000988 | 0.001066 | 0.001086 | 0.0011041 |
| 0.01 | 10 | 0.1 | |||||
| 0.01 | 100 | 0.02 | 0.02 | 0.03 | |||
| 0.01 | 1000 | 0.006 | 0.006 | 0.008 | 0.013 | 0.014 | 0.015 |
| 0.01 | 10000 | 0.0086 | 0.0089 | 0.0092 | 0.0109 | 0.0114 | 0.0118 |
| 0.01 | 50000 | 0.0093 | 0.0095 | 0.0097 | 0.0104 | 0.0106 | 0.0108 |
| 0.01 | 100000 | 0.0095 | 0.0096 | 0.0098 | 0.0103 | 0.0104 | 0.0106 |
| 0.01 | 250000 | 0.0097 | 0.0098 | 0.0099 | 0.0102 | 0.0103 | 0.0104 |
| 0.01 | 500000 | 0.0098 | 0.0099 | 0.0099 | 0.0102 | 0.0102 | 0.0103 |
| 0.1 | 10 | 0.2 | 0.2 | 0.3 | |||
| 0.1 | 100 | 0.05 | 0.06 | 0.07 | 0.13 | 0.14 | 0.15 |
| 0.1 | 1000 | 0.086 | 0.0889 | 0.093 | 0.108 | 0.1121 | 0.117 |
| 0.1 | 10000 | 0.0954 | 0.0963 | 0.0979 | 0.1028 | 0.1041 | 0.1055 |
| 0.1 | 50000 | 0.098 | 0.0986 | 0.0992 | 0.1014 | 0.1019 | 0.1024 |
| 0.1 | 100000 | 0.0987 | 0.099 | 0.0994 | 0.1011 | 0.1014 | 0.1018 |
| 0.1 | 250000 | 0.0993 | 0.0995 | 0.0998 | 0.1008 | 0.1011 | 0.1013 |
| 0.1 | 500000 | 0.0996 | 0.0998 | 0.1 | 0.1007 | 0.1009 | 0.101 |
| 0.5 | 10 | 0.2 | 0.3 | 0.4 | 0.6 | 0.7 | 0.8 |
| 0.5 | 100 | 0.42 | 0.44 | 0.46 | 0.54 | 0.56 | 0.58 |
| 0.5 | 1000 | 0.473 | 0.478 | 0.486 | 0.513 | 0.52 | 0.525 |
| 0.5 | 10000 | 0.4922 | 0.4939 | 0.4959 | 0.5044 | 0.5061 | 0.5078 |
| 0.5 | 50000 | 0.4962 | 0.4968 | 0.4978 | 0.5018 | 0.5028 | 0.5036 |
| 0.5 | 100000 | 0.4974 | 0.4979 | 0.4986 | 0.5014 | 0.5021 | 0.5027 |
| 0.5 | 250000 | 0.4984 | 0.4987 | 0.4992 | 0.5008 | 0.5013 | 0.5017 |
| 0.5 | 500000 | 0.4988 | 0.4991 | 0.4994 | 0.5006 | 0.5009 | 0.5011 |
Посмотрим случаи с 10% конверсией и с низкой 0.01% конверсией, т.к. на них хорошо видны все особенности работы с сэмплированием.
При 10% конверсии картина выглядит довольно простой:

Точки — это края 5-95% доверительного интервала, т.е. делая сэмпл мы будем в 90% случаев получать CR на выборке внутри этого интервала. Вертикальная шкала — размер сэмпла (шкала логарифмическая), горизонтальная — значение коэффициента конверсии. Вертикальная черта — «истинный» CR.
Мы тут видим то же, что мы видели из теоретической модели: точность растет по мере роста размера сэмпла, при этом одна довольно быстро «сходится» и сэмпл получает результат близкий к «истинному». Всего на 1000 сэмпле мы имеем 8.6% — 11.7%, что для ряда задач будет достаточно. А на 10 тысячах уже 9.5% — 10.55%.
Куда хуже дела обстоят с редкими событиями и это согласуется с теорией:

У низкого коэффициента конверсии в 0.01% принципе проблемы на статистике в 1 млн наблюдений, а с сэмплами ситуация оказывается еще хуже. Ошибка становится просто гигантской. На сэмплах до 10 000 метрика в принципе не валидна. Например, на сэмпле в 10 наблюдений мой генератор просто 1000 раз получил 0 конверсию, поэтому там только 1 точка. На 100 тысячах мы имеем разброс от 0.005% до 0.0016%, т.е мы можем ошибаться почти в половину коэффициента при таком сэмплировании.
Также стоит отметить, что когда вы наблюдаете конверсию такого маленького масштаба на 1 млн испытаний, то у вас просто большая натуральная ошибка. Из этого следует, что выводы по динамике таких редких событий надо делать на действительно больших выборках иначе вы просто гоняетесь за призраками, за случайными флуктуациями в данных.
Выводы:
Population vs sample
First, you need to understand the difference between a population and a sample, and identify the target population of your research.
- The population is the entire group that you want to draw conclusions about.
- The sample is the specific group of individuals that you will collect data from.
The population can be defined in terms of geographical location, age, income, and many other characteristics.
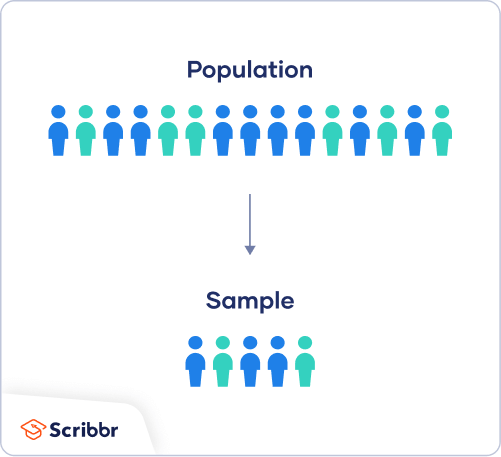
It is important to carefully define your target population according to the purpose and practicalities of your project.
If the population is very large, demographically mixed, and geographically dispersed, it might be difficult to gain access to a representative sample.
Sampling frame
The sampling frame is the actual list of individuals that the sample will be drawn from. Ideally, it should include the entire target population (and nobody who is not part of that population).
Example
You are doing research on working conditions at Company X. Your population is all 1000 employees of the company. Your sampling frame is the company’s HR database which lists the names and contact details of every employee.
Sample size
The number of individuals you should include in your sample depends on various factors, including the size and variability of the population and your research design. There are different sample size calculators and formulas depending on what you want to achieve with statistical analysis.
Особенности применения сэмплинга
Кроме выбора собственно метода сэмплинга, который наилучшим образом подходит к решаемой задаче и используемым данным, аналитику требуется принять решение о некоторых особенностях его применения. Обычно это связано с выбором, будет ли реализован сэмплинг с возвратом или без, а также определить размер полученной выборки.
Сэмплинг с возвратом (заменой) — это методика построения выборок, при которой каждый объект исходной совокупности может быть выбран более, чем один раз. Т.е. предполагается что отбираемый объект не перемещается, а копируется в выборку, оставаясь в исходной совокупности.
Сэмплинг без возврата (замены) предполагает, что каждый объект совокупности может быть выбран только один раз. Т.е. объект перемещается из исходной совокупности в выборку.
Сэмплинг с возвратом используется в том случае, если количество уникальных объектов совокупности недостаточно для формирования выборки требуемого объема, что компенсируется возможностью многократного выбора объектов. Недостатком подхода является появление в выборке дубликатов. Таким образом, сэмплинг с заменой позволяет увеличить объем выборки, но не её репрезентативность.
Определение объёма выборки. Определение числа объектов, из которого будет состоять выборка, является важным элементом любого эмпирического исследования в статистике или анализе данных, по результатам которого должны быть сделаны вывод о свойствах совокупности на основе свойств выборки.
На практике объём выборки обычно определяется на основе затрат, времени или удобства сбора данных, а также необходимости достижения необходимой репрезентативности и полноты.
В заключении следует отметить, что несмотря на общепринятую схему классификации, которая наиболее часто приводится в литературе, методология сэмплинга не имеет чётких границ. Вообще говоря, к сэмплингу можно отнести любой метод отбора данных, который формирует выборки, с помощью которых пользователь может решать свои задачи. Например, в сэмплинге могут использоваться алгоритмы фильтрации строк.
При этом достижение репрезентативности, полноты и точности выборки не является приоритетным. Главное, чтобы она была полезной для решения практической задачи. Вопрос только в корректности построенных с её помощью моделей, сделанных выводах и обобщениях.
Другие материалы по теме:
What is Sampling?
Let’s start by formally defining what sampling is.
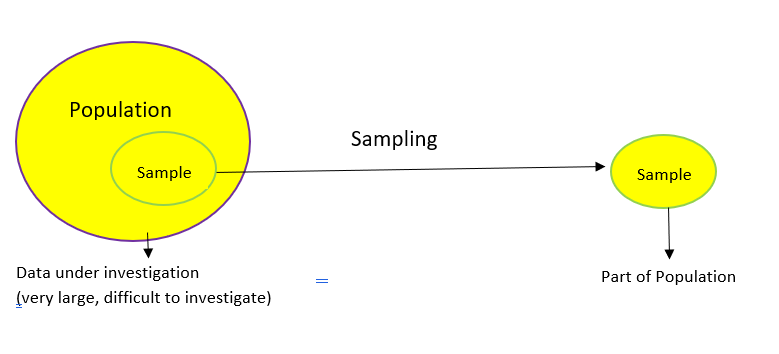
The above diagram perfectly illustrates what sampling is. Let’s understand this at a more intuitive level through an example.
We want to find the average height of all adult males in Delhi. The population of Delhi is around 3 crore and males would be roughly around 1.5 crores (these are general assumptions for this example so don’t take them at face value!). As you can imagine, it is nearly impossible to find the average height of all males in Delhi.
It’s also not possible to reach every male so we can’t really analyze the entire population. So what can we do instead? We can take multiple samples and calculate the average height of individuals in the selected samples.

But then we arrive at another question – how can we take a sample? Should we take a random sample? Or do we have to ask the experts?
Let’s say we go to a basketball court and take the average height of all the professional basketball players as our sample. This will not be considered a good sample because generally, a basketball player is taller than an average male and it will give us a bad estimate of the average male’s height.
Here’s a potential solution – find random people in random situations where our sample would not be skewed based on heights.
Sampling Error vs. Non-sampling Error
There are different types of errors that can occur when gathering statistical data. Sampling errors are the seemingly random differences between the characteristics of a sample population and those of the general population. Sampling errors arise because sample sizes are inevitably limited. (It is impossible to sample an entire population in a survey or a census.)
A sampling error can result even when no mistakes of any kind are made; sampling errors occur because no sample will ever perfectly match the data in the universe from which the sample is taken.
Company XYZ will also want to avoid non-sampling errors. Non-sampling errors are errors that result during data collection and cause the data to differ from the true values. Non-sampling errors are caused by human error, such as a mistake made in the survey process.
If one group of consumers only watches five hours of video programming a week and is included in the survey, that decision is a non-sampling error. Asking questions that are biased is another type of error.
Описание алгоритма
Узел Сэмплинг реализует пять методов отбора записей (единиц) в выборку из набора данных (генеральной совокупности). При этом формируется репрезентативное подмножество, обеспечивающее информационную насыщенность выборки.
Случайный: выборка производится случайным образом из всей совокупности;
Равномерный случайный: все записи исходной совокупности разделяются на группы, в каждой из которых содержится одинаковое число записей. Затем из каждой группы случайным образом выбирается одна запись и помещается в результирующую выборку. Выборка, полученная в результате сэмплинга, будет состоять из записей, случайным образом отобранных из каждой группы.
Стратификационный сэмплинг. Если исходная совокупность существенно неоднородна, случайный сэмплинг работает плохо и лучших результатов удается добиться, если производить выборку каждой группы, независимо от других групп. Стратификационный сэмплинг выполняется в два этапа:
- Стратификация – группировка элементов исходной совокупности в относительно однородные подгруппы, которые называются стратами или слоями.
- Случайный сэмплинг – случайная выборка из каждого слоя по отдельности.
Последовательный: выборка производится последовательным образом из всей совокупности, пока не будет достигнут требуемый объем.
Отбор со смещением. Иногда исследователи сталкиваются с ситуацией, когда важные с точки зрения решаемой задачи объекты или события представлены очень небольшим числом наблюдений, что не позволяет выполнить их достоверный анализ. В таких случаях применяется Отбор со смещением – «перевзвешивание» примеров, или изменение соотношения принадлежности записей к классам.
Искусственное усиление представительства редких событий или объектов выборки рассмотрено в статье «Различные стратегии сэмплинга в условиях несбалансированности классов».
Какой бывает сэмплинг?
Современные специалисты в области маркетинга и btl коммуникации выделяют несколько основных видов сэмплинга:
Horeca sampling
Эта разновидность сэмплинга охватывает такие места продаж, как кафе, бары, рестораны и т.д и в основном рассчитана на продвижение нового продукта или бренда, относящегося к категории алкогольных или безалкогольных напитков и табачной продукции. Суть механики в том, чтобы перед приобретением того или иного напитка дать возможность покупателю познакомиться с его свойствами, то есть попробовать на вкус.
Хоть процент прироста продаж по результатам проведения подобных акций, как правило, не является значительным, но узнаваемость бренда и лояльность целевой аудитории по отношению к компании-производителю становится выше. В основном подобная механика применяется для продвижения элитного алкоголя и дорогостоящих сигарет с расчетом на целевую аудиторию с доходом выше среднего.
Pack swap
Данная разновидность промо механики предполагает обмен и касается тех товаров, которые потребитель может предположительно носить с собой (сигареты, жевательная резинка, помада и другое). К примеру, подобные промо проекты могут проводиться на улице или в местах наибольшего скопления людей, суть – предложение обмена пачки сигарет (или другого продукта) на новый аналогичный товар, но другого бренда.
Механика хороша тем, что среди прочей пользы можно провести маркетинговое исследование спроса. Однако в тоже время данный вид сэмплинга достаточно сложен в реализации, так как потребитель не всегда готов легко отказаться от привычного ему продукта, плюс немаловажную роль здесь играет ценовая категория товара.
Wet sampling
Самая популярная разновидность сэмплинга среди потребителей, которая по сути представляет собой дегустацию. Местом проведения таких мероприятий, как правило, являются точки продаж, реализующие продвигаемые товары. Круг продуктов питания, которые могут быть использованы в качестве предмета продвижения, неограничен: сыр, йогурт, чай, сок, колбаса и многое другое.
Предложение попробовать продукт на вкус – это отличный маркетинговый ход, который срабатывает в качестве «приманки» для потребителей почти всегда. Результат подобных экспериментов — повышение продаж и спроса на продукцию рекламодателя. А если учесть общеизвестный факт, что голодный человек, чувствуя приятный запах еды, покупает больше сытого, то возможность покупки товара, который ещё и можно попробовать на вкус повышает шансы рекламной кампании на успех в десятки раз.
Dry sampling
Механика полезная и эффективная, но в плане анализа результативности сложнее остальных. В данном случае сэмплинг представляет собой раздачу пробных экземпляров продукции, которые можно попробовать исключительно в домашних условиях. К этой категории можно отнести и прямое распространение продукции, примотки товаров к сопутствующим категориям продуктам, ограниченные продажи экземпляров по выгодной цене для сомневающихся потребителей.
 Например, довольно часто пробники или тестеры распространяются с помощью журналов (вклеивание), чаще всего таким образом продвигаются шампуни, средства личной гигиены, косметика, приправы, сухие смеси для приготовления и другое. Изучить реакцию целевой аудитории на продукт в данном случае сложно, так как образец продукции покупатель уносит собой и может протестировать не сразу, а через значительный промежуток времени.
Например, довольно часто пробники или тестеры распространяются с помощью журналов (вклеивание), чаще всего таким образом продвигаются шампуни, средства личной гигиены, косметика, приправы, сухие смеси для приготовления и другое. Изучить реакцию целевой аудитории на продукт в данном случае сложно, так как образец продукции покупатель уносит собой и может протестировать не сразу, а через значительный промежуток времени.
Несмотря на то, какой именно вид сэмплинга будет использован в рамках рекламной кампании, нельзя забывать про его основную цель – донесение актуальной и полезной информации до потенциального покупателя и мотивация на приобретение рекламируемого продукта.
Виды сэмплинга
Сэмплинг — отличный способ стимулирования продаж в ритейле. Его организация в точках продаж позволяет подключать эмоции потенциальных покупателей и мотивирует их делать спонтанные покупки. Однако, сэмплинг не обязательно проводят на территории магазина или торгового центра. Некоторые компании предлагают образцы своей продукции прямо на улице. Ознакомьтесь подробнее с видами сэмплинга.
- Обмен (Switch-sampling). Подразумевает обмен наполовину пустой упаковки используемого товара на новый. Такой подход помогает клиенту сравнить качество аналогичных товаров.
- Сухой сэмплинг (dry sampling). Предполагает рекламу продукта в точке продажи. Потенциальным покупателям предлагают взять с собой пробник бальзама для волос, крема, зубной пасты или другого товара.
- Влажный сэмплинг (wet sampling). Предоставляет целевой аудитории возможность продегустировать товар на месте. Например, колбасные изделия, сыр, масло, йогурт и так далее.
- HoReCa сэмплинг (Hotel-Restaurant-Cafe sampling). Это дегустация алкогольных и безалкогольных напитков, а также сигарет. Такой сэмплинг чаще всего организовывают в ресторанах, кафе, гостиницах и преподносят как комплимент от заведения или подарок при заказе на определенную сумму.
- Домашний сэмплинг (house-to-house sampling). Предполагает рассылку примеров товара почтой. Это может быть мини-версия продукта или печатная реклама с образцами и многое другое.
Теперь, когда вы знаете виды сэмплинга, самое время узнать, как правильно его организовать.
Как организовать сэмплинг
- Установите цели и задачи сэмплинга
- Подберите продукт и установите объем сэмпла
- Выберите время проведения сэмплинга
- Выберите место проведения сэмплинга
- Соберите команду промоутеров
Чтобы организовать эффективный сэмплинг, воспользуйтесь следующими полезными рекомендациями.
Установите цели и задачи сэмплинга. Прежде чем приступать к организационным вопросам, подумайте, зачем вам нужна эта акция, чего вы хотите достичь с ее помощью. Подготовьте маркетинговый план и по пунктам пропишите пути достижения каждой задачи.
Подберите продукт и установите объем сэмпла
В этом вопросе важно полагаться на интересы и предпочтения целевой аудитории. Тщательно продумайте, что вы будете предлагать, как и в каком количестве
Пропишите расходы, необходимые для организации сэмплинга.
Выберите время проведения сэмплинга. Установите, когда лучше всего взаимодействовать с целевой аудиторией. Сэмплинг может проводится на протяжении всего дня или в какие-то определенные часы. Такой подход позволит сконцентрировать усилия на потенциальных покупателях и не распылять свои ресурсы.
Выберите место проведения сэмплинга. На основании данных о своей целевой аудитории выявите наиболее релевантные точки проведения акции. Подумайте, где больше всего ваших потенциальных покупателей. При этом помните, что клиент должен иметь возможность купить товар, иначе он может передумать и все усилия будут сведены к минимуму.
Соберите команду промоутеров. В этом вопросе важно учесть пол, возраст и другие характеристики, которые могут влиять на уровень доверия вашей целевой аудитории.
При правильном подходе сэмплинг способен увеличить объем продаж на 200-300%. Однако, эффективность не всегда можно измерить в денежном эквиваленте, ведь ознакомление целевой аудитории с продукцией это еще и работа на перспективу. Используйте инструменты ATL и BTL-рекламы, задействуйте мессенджеры и социальные сети, чтобы увеличить количество точек контакта с клиентом.
Примечания[править]
- I. Mani, J. Zhang. “kNN approach to unbalanced data distributions: A case study involving information extraction,” In Proceedings of the Workshop on Learning from Imbalanced Data Sets, pp. 1-7, 2003.
- D. Wilson, “Asymptotic Properties of Nearest Neighbor Rules Using Edited Data,” IEEE Transactions on Systems, Man, and Cybernetrics, vol. 2(3), pp. 408-421, 1972.
- N. V. Chawla, K. W. Bowyer, L. O. Hall, W. P. Kegelmeyer, “SMOTE: Synthetic minority over-sampling technique,” Journal of Artificial Intelligence Research, vol. 16, pp. 321-357, 2002.
- H. Han, W.-Y. Wang, B.-H. Mao, “Borderline-SMOTE: A new over-sampling method in imbalanced data sets learning,” In Proceedings of the 1st International Conference on Intelligent Computing, pp. 878-887, 2005.
- H. M. Nguyen, E. W. Cooper, K. Kamei, “Borderline over-sampling for imbalanced data classification,” In Proceedings of the 5th International Workshop on computational Intelligence and Applications, pp. 24-29, 2009.
- G. E. A. P. A. Batista, A. L. C. Bazzan, M. C. Monard, “Balancing training data for automated annotation of keywords: A case study,” In Proceedings of the 2nd Brazilian Workshop on Bioinformatics, pp. 10-18, 2003.
- G. E. A. P. A. Batista, R. C. Prati, M. C. Monard, “A study of the behavior of several methods for balancing machine learning training data,” ACM Sigkdd Explorations Newsletter, vol. 6(1), pp. 20-29, 2004.
- X.-Y. Liu, J. Wu and Z.-H. Zhou, “Exploratory undersampling for class-imbalance learning,” IEEE Transactions on Systems, Man, and Cybernetics, vol. 39(2), pp. 539-550, 2009.
- C. Chao, A. Liaw, and L. Breiman. «Using random forest to learn imbalanced data.» University of California, Berkeley 110 (2004): 1-12.
- Hido, Shohei & Kashima, Hisashi. (2008). Roughly Balanced Bagging for Imbalanced Data. 143-152. 10.1137/1.9781611972788.13.
Литература
- Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation
of word representations in vector space. CoRR, abs/1301.3781, - Tomas Mikolov, Ilya Sutskever, Kai Chen, Gregory S. Corrado, and Jeffrey Dean. Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems 2013. Proceedings of a meeting held December 5-8, 2013, Lake Tahoe, Nevada, United States, pages 3111–3119, 2013.
- Morin, F., & Bengio, Y. Hierarchical Probabilistic Neural Network Language Model. Aistats, 5, 2005.
- Jeffrey Pennington, Richard Socher, and Christopher D. Manning. GloVe: Global Vectors for Word Representation. 2014.
- Piotr Bojanowski, Edouard Grave, Armand Joulin, and Tomas Mikolov. Enriching word vectors
with subword information. arXiv preprint arXiv:1607.04606, 2016.
Introduction
Here’s a scenario I’m sure you are familiar with. You download a relatively big dataset and are excited to get started with analyzing it and building your machine learning model. And snap – your machine gives an “out of memory” error while trying to load the dataset.
It’s happened to the best of us. It’s one of the biggest hurdles we face in data science – dealing with massive amounts of data on computationally limited machines (not all of us have Google’s resource power!).
So how can we overcome this perennial problem? Is there a way to pick a subset of the data and analyze that – and that can be a good representation of the entire dataset?

Yes! And that method is called sampling. I’m sure you’ve come across this term a lot during your school/university days, and perhaps even in your professional career. Sampling is a great way to pick up a subset of the data and analyze that. But then – should we just pick up any subset randomly?
Well, we’ll discuss that in this article. We will talk about eight different types of sampling techniques and where you can use each one. This is a beginner-friendly article but some knowledge about descriptive statistics will serve you well.
If you’re new to statistics and data science, I encourage you to check out our two popular courses:
- Introduction to Data Science
- Applied Machine Learning: Beginner to Professional
Downsampling
Итак, при уменьшении частоты дискретизации упрощённо происходит два этапа:
- Цифровая фильтрация сигнала для того, чтобы удалить высокочастотные составляющие, которые не удовлетворяют пределу Найквиста для новой частоты дискретизации;
- Удаление или (отбрасывание) лишних отсчетов (сохраняется каждый N-й отсчёт). Здесь следует пояснить, что при программной реализации алгоритма децимации «лишние» отсчёты не удаляются, а просто не вычисляются (отбрасываются). При этом число обращений к цифровому фильтру уменьшается в определённое количество раз.
Так вот. Второй этап удаление или (отбрасывание) лишних отсчетов в англоязычной литературе иногда обозначают термином downsampling, что по сути может употребляться как синоним термина «децимация».


